Google представила Gemini Omni — новую модель, которая сможет генерировать видео из любого сочетания исходников: текста, изображения, аудио или другого видео. Главное отличие от существующих видеогенераторов — пользователь сможет править ролик в обычном диалоге, как в чате с человеком. Первая версия модели, Gemini Omni Flash, уже доступна подписчикам Google AI Plus, Pro и Ultra в приложении Gemini и Google Flow, а также бесплатно — в YouTube Shorts и YouTube Create.

В диалоге пользователь сможет менять что угодно — окружение, действия, ракурс, стиль — и модель будет сохранять ключевые элементы сцены. Персонажи останутся такими же, физика мира — последовательной, а каждая правка будет строиться на предыдущей. Например, можно будет сгенерировать видео скрипача, попросить Omni «перенести скрипача в этот лес», затем — «изменить ракурс на вид из-за плеча». Модель выполнит обе правки и не потеряет нить сцены.
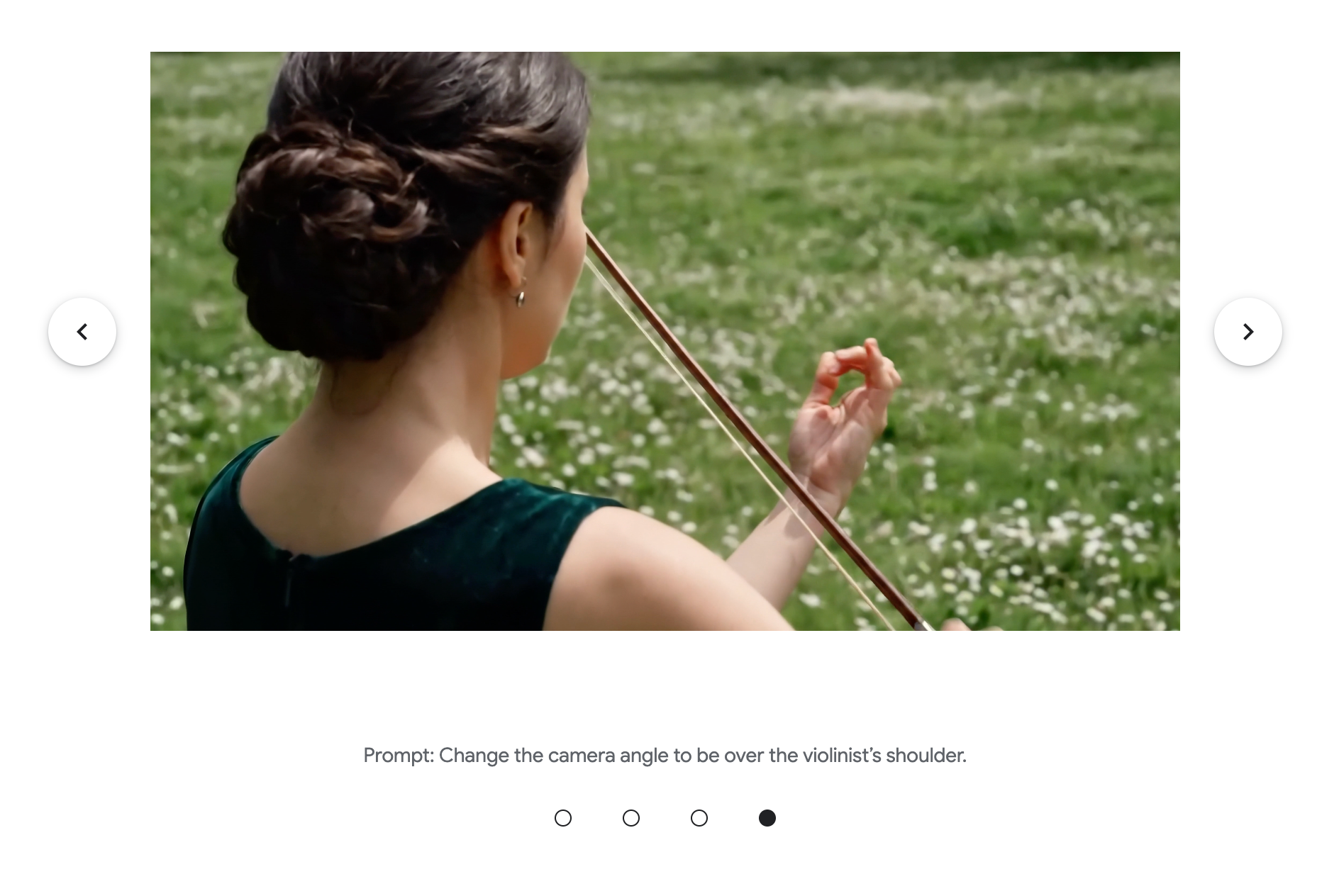
Omni не просто генерирует красивые сцены — она использует знания Gemini о реальном мире. Модель будет лучше понимать физику (гравитацию, кинетику, движение жидкостей), а также сможет связывать визуальные образы со смыслом. По одному короткому промпту Omni соберет, например, объясняющее видео про сворачивание белка в стилистике пластилиновой анимации.
Главная фишка — комбинация исходников. Пользователь сможет одновременно подать на вход картинку, видео, аудио и текст, и Omni объединит их в единый ролик.
В ближайшие недели Omni Flash появится в API для разработчиков и корпоративных клиентов. Google также пообещала позже выпустить версии для генерации изображений и аудио.
Источник: The Keyword (Google Blog)