Mistral представила OCR 4 — модель для распознавания и разбора документов. Она сможет извлекать текст, определять расположение заголовков, таблиц, формул и подписей, а также показывать уверенность в каждом распознанном слове. Обработка 1000 страниц через программный интерфейс обойдется в $4, а в пакетном режиме — в $2.
Предыдущие версии таких систем в основном превращали страницу в сплошной текст и таблицы. После этого разработчикам приходилось отдельно восстанавливать структуру документа и проверять, где именно находился каждый фрагмент. OCR 4 сможет сразу возвращать координаты элементов и указывать их тип, поэтому сервисы на ее основе смогут подсвечивать источник ответа, находить поля в счетах и отправлять сомнительные фрагменты на ручную проверку.
Модель сможет работать с файлами PDF, DOC, PPT и OpenDocument на 170 языках. Компании смогут использовать ее для обработки договоров, счетов, презентаций, научных отчетов и архивов, а затем добавлять извлеченные данные в корпоративный поиск или базы знаний.
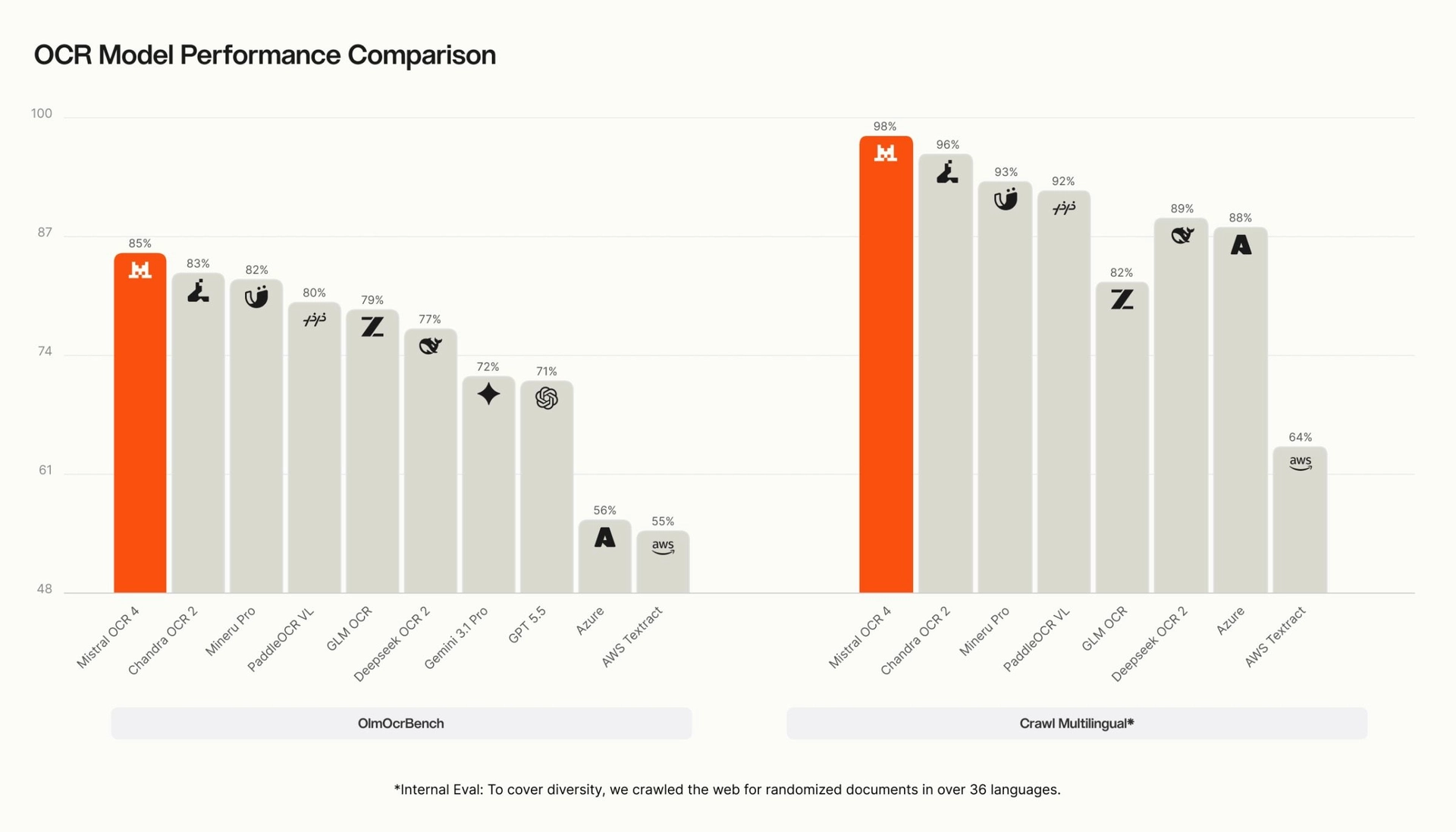
По данным Mistral, независимые оценщики сравнили результаты на более чем 600 документах и предпочли OCR 4 другим протестированным системам в среднем в 72% случаев. Модель также получила 85,20 балла в тесте OlmOCRBench. При этом сама компания предупредила, что автоматические тесты не всегда корректно оценивают формулы, многоколоночные страницы и разные варианты одинаковой разметки.
OCR 4 уже можно подключить через Mistral Studio, Amazon SageMaker и Microsoft Foundry. Корпоративные клиенты смогут установить модель на собственной инфраструктуре, чтобы документы с персональными, финансовыми или коммерческими данными не покидали компанию.
Источник: Mistral AI