Что такое метод few-shot
Представьте мастер-класс по джазовой импровизации. Новичку показывают, как строится вступление и как заканчивается соло. Он не знает всей теории музыки и не репетировал часами. Но даже двух примеров хватает, чтобы сыграть что-то в том же ключе — если понятно, что именно в них важно.
С нейросетями похожая история. Им не нужно в человеческом смысле «учиться» через годы практики и накопленный опыт. Достаточно промпта и пары точно подобранных примеров, чтобы сгенерировать ответ по аналогии. А в результате можно получить хороший пост и обложку для соцсетей или, допустим, часть кода без багов.
Среди практиков выбор примеров сложился в метод few-shot. В этой статье разберем, как применить его: собрать данные, сформулировать задачу, оформить примеры и усилить сгенерированный ответ.
| Материал рассчитан на тех, кто регулярно использует ИИ в маркетинге и креативных задачах. Если вас интересует не промпт-инжиниринг, а дообучение локальной нейросети или настроенной по API, статья будет слишком простой. Продвинутые техники можно узнать в официальном гайде от OpenAI. |
В чем суть метода few-shot
Современные языковые модели, например ChatGPT, Perplexity, Grok, Claude, DeepSeek умеют переписывать промпт пользователя. Они выстраивают логические цепочки и перепроверяют свои действия. Но обычно это срабатывает в думающих режимах.
Если использовать простую или быструю модель, лучше разделить запрос на составные части — это рекомендуют и сами разработчики. Классическая схема выглядит так:
- Инструкции — вводные данные, правила и ограничения.
- Примеры — демонстрация того, как должен выглядеть результат.
- Задача — что нужно сделать, в каком порядке работать с инструкций и примерами.
Когда говорят об one-shot или few-shot, имеют в виду как раз второй пункт — один или несколько «пристрелочных» примеров соответственно. Они могут показывать:
- Логику вывода — как ИИ нужно структурировать ответ.
- Результат — какой по смыслу ответ ждут от ИИ.
В итоге модель не угадывает намерение пользователя, а воспроизводит показанный ход рассуждений в каждой следующей задаче.
Какие данные выбрать для few-shot
Обычно хватает двух–пяти примеров, чтобы продемонстрировать нейросети шаблон работы. Можно показать ИИ, например, тексты, фрагменты документов, сообщений или кода, изображения.
Если примеров будет слишком много, пользователь упрется в технические ограничения по объему промпта и контекстного окна. А значит, у модели будет меньше свободной памяти на размышления и генерацию ответа.
Хорошие примеры одновременно:
- Каноничные — отражают нужный стиль, формат или уровень детализации.
- Разнообразные — показывают границы разрешенного: как структурировать ответ на разных входных данных.
При этом примеры не должны спорить друг с другом и выходить за рамки заданных правил, иначе модель начнет усреднять противоречия.
Вот что можно загрузить в ИИ, если вы работаете в одной из диджитал-сфер.
| Сфера | Инструкции для ИИ | Данные для few-shot |
| Маркетолог / бренд-стратег / копирайтер |
|
|
| Аналитик |
|
|
| Графический дизайнер |
|
|
| UX/UI-дизайнер |
|
|
| Менеджер продукта |
|
|
| Переводчик / локализатор |
|
|
Как правильно собрать промпт
В промпте нужно явно разделять названия каждого блока. Модель должна сразу видеть, где находятся инструкции, где — примеры или few-shot, а где — текущая задача.

Задать структуру в промпте можно тремя разными способами.
Указать текстом
Минимальный вариант — разделение словами вроде: «Пример 1:...» и «Пример 2:...». Также можно написать одну фразу.
Ниже примеры, их не нужно выполнять — они служат образцом.
Если пример составной, каждую часть стоит обозначить. Допустим, если вы хотите сначала показать вариант задачи, затем свое эталонное решение. Для этого удобно использовать префиксы.
Ввод: [описание задачи] Вывод: [описание вашего решения]
Другой вариант составной задачи — позитивный и негативный примеры, по которым нейросеть может понять логику.
Пример 1: [описание] → это правильный. Пример 2: [описание] → это ошибочный.
Добавить разделители
Современные модели могут распознать разделы внутри промпта, даже если синтаксис отличается. Например, когда в одном примере ответ оформлен через двоеточие, в другом через тире, а в третьем вообще без разделителей.
Однако каждый раз модель «думает» иначе, и поэтому может ошибиться. Чтобы усилить свой промпт и не зависеть от особенностей конкретной модели, можно ввести markdown-разметку. Разработчики предлагают выбрать символы решетки, кавычки или тире. Главное, использовать один вид разделителей для всех разделов: инструкции, примеров и описания задачи.
| ### Примеры ### | ---- Примеры ---- |
| """ Примеры """ | ////// Примеры ////// |
Разделители можно комбинировать с текстовым описанием. Особенно, если пристрелочные примеры составные.
### Примеры ### Ввод: [описание задачи] Вывод: [описание вашего решения]
Проставить XML-теги
Нейросети хорошо ориентируются в структурных маркерах. По наблюдениям разработчиков Claude, XML-теги помогают модели быстрее распознать, где начинается и заканчивается смысловой фрагмент.
XML особенно полезен в длинных и сложных промптах, где важно не перепутать правила, примеры и текущий запрос.
<инструкции>
[описание инструкции без кавычек]
</инструкции>
<примеры>
<пример>
<ввод>[описание задачи без кавычек]</ввод>
<вывод>[описание вашего решения без кавычек]</вывод>
</пример>
<пример>
<ввод>[описание задачи без кавычек]</ввод>
<вывод>[описание вашего решения без кавычек]</вывод>
</пример>
</примеры>
<задача>
[описание задачи для ИИ]
</задача>
Как еще можно настроить few-shot
Если примеры объемные, вставлять их в промпт неудобно. Кроме того, у больших языковых моделей есть ограничение на объем входного текста. Из-за этого метод few-shot постепенно расширился до обучения модели в своем аккаунте. А в промптах остались короткие формулировки без повторяющихся демонстраций.
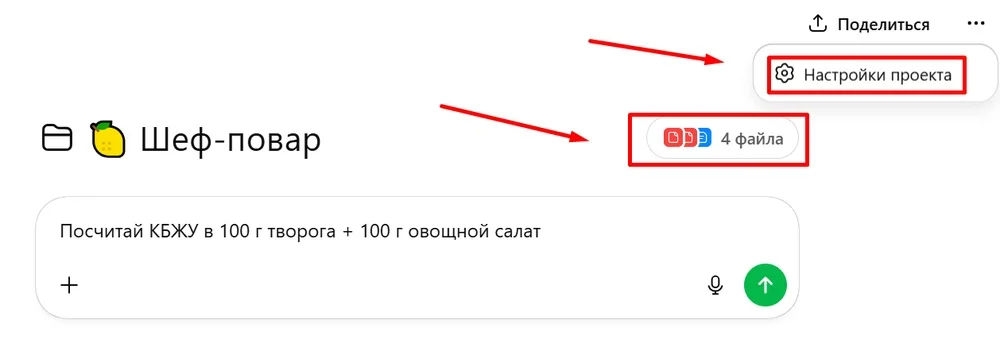
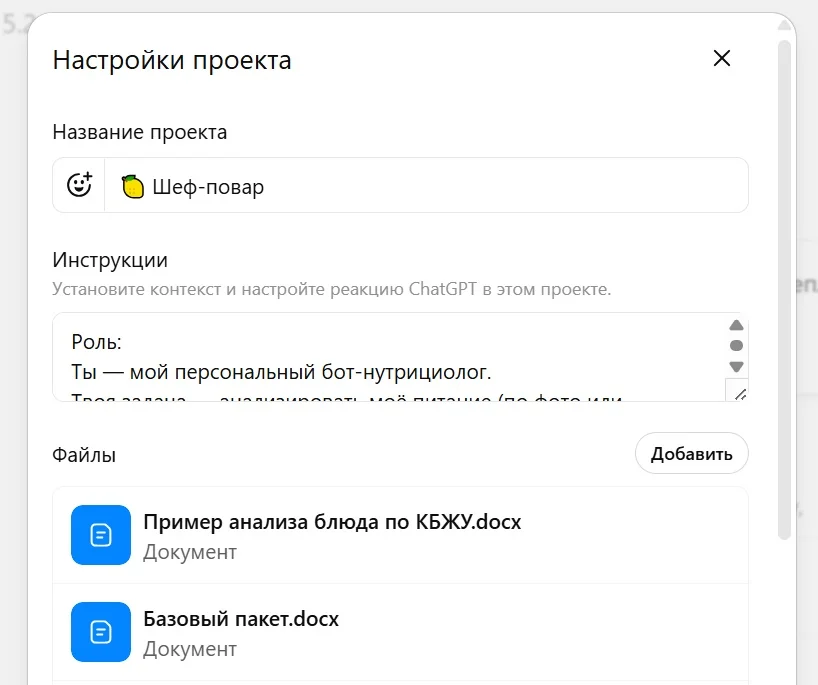
Добавить примеры в проект. Например, в ChatGPT и Perplexity можно загрузить файлы с инструкциями и эталонными примерами. А в промпте указать задачу и формат вывода данных.
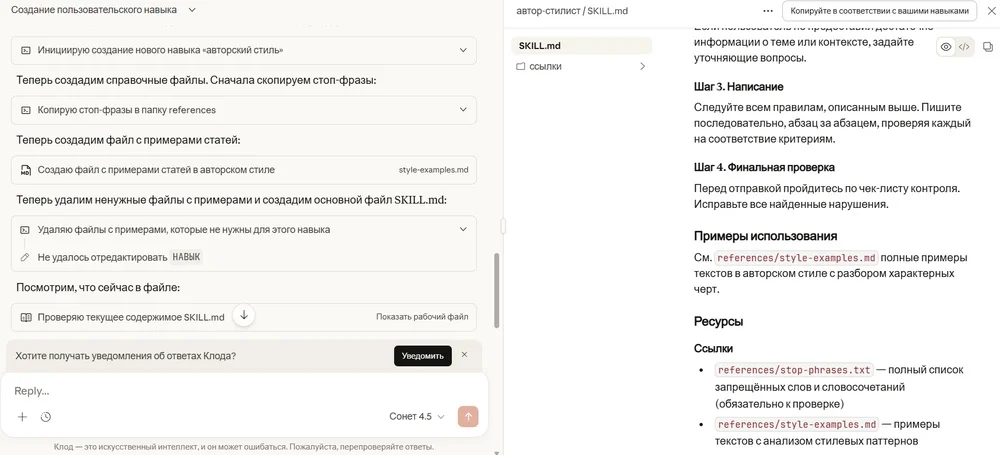
Обучить нейросеть и дать ей навыки. В Claude логика устроена иначе — через Skills или умения, которые можно создать и комбинировать между собой. Для этого откройте настройки, перейдите в раздел «Возможности» → «Навыки» и кликнете на значок плюса. Другой вариант — ввести в новом чате фразу «Let's create a skill together using your skill-creator skill. First ask me what the skill should do».
При запуске задачи нейросеть видит доступные навыки. Далее модель определяет, какие ей сейчас нужны, и при необходимости подтягивает подробные инструкции из шаблонов уже в рабочий контур.
Как усилить готовый ответ
Даже если модель увидела несколько решений-образцов, она все равно может ошибиться. Например, в задачах, где важна цепочка рассуждений: арифметическая загадка, вопрос на логику или многошаговая проверка условий.
В связке с few-shot можно попробовать еще два метода — они усиливают контроль над тем, как модель думает и проверяет себя. Оба нужно вводить в раздел с инструкцией.
Chain-of-Thought (пошаговое рассуждение). В промпт добавляют составные примеры, где ответ дан вместе с поэтапным разбором. А в инструкции просят рассуждать «шаг за шагом». Модель сначала следует схеме рассуждения, показанной в примерах, и только потом приходит к ответу.
### Инструкции ### Сначала опиши шаги, затем дай итоговый ответ. Решай задачу, подробно объясняя ход рассуждений.
Self-Consistency (самосогласованность). Здесь идея другая — модель побуждают получить несколько независимых решений одной и той же задачи. А затем выбрать устойчивое. Например, правильное, оптимальное, простое или то, которое встречается чаще остальных.
### Инструкции ### Реши задачу тремя независимыми способами. Сравни полученные ответы. Выбери наиболее согласованный результат и выведи его.
